Machine Learning Models
Introduction
In today's data-driven world, machine learning has taken center stage. But what exactly are machine learning models, and why are they so crucial?
Machine learning has rapidly become one of the most transformative technologies of our time. From predicting customer preferences in e-commerce to diagnosing diseases in healthcare, machine learning models are driving innovation across industries. In this comprehensive guide, we'll take you on a journey through the world of machine learning models, providing you with the knowledge and tools to understand and use them effectively.
You may also like to read:
What Are Machine Learning Models?
At its core, machine learning is a subset of artificial intelligence that enables computers to learn from data and make predictions or decisions without explicit programming. Machine learning models are algorithms designed to perform specific tasks based on patterns and information extracted from data.
There are several types of machine learning models, each tailored to different problem-solving scenarios:
1. Supervised Learning Models
Supervised learning involves training a model on labeled data, where the algorithm learns to map input data to the correct output. Some commonly used supervised learning models include:
- Linear Regression: Used for regression tasks to predict continuous values.
- Logistic Regression: Applied in classification problems, where the outcome is binary.
- Decision Trees: Useful for both classification and regression tasks, providing a clear, interpretable model.
- Random Forest: A robust ensemble method built on decision trees, offering improved accuracy.
- Support Vector Machines (SVM): Effective for binary classification tasks, finding a hyperplane that best separates data points.
2. Unsupervised Learning Models
Unsupervised learning deals with unlabeled data, aiming to discover patterns or structures within the data. Common unsupervised models include:
- K-Means Clustering: Used for clustering data into distinct groups based on similarity.
- Hierarchical Clustering: Builds a hierarchy of clusters, revealing nested structures.
- Principal Component Analysis (PCA): Reduces dimensionality while preserving data variance.
- Gaussian Mixture Models (GMM): Represents data as a mixture of Gaussian distributions.
3. Reinforcement Learning Models
Reinforcement learning focuses on training agents to make sequential decisions to maximize a reward signal. Key reinforcement learning models include:
- Q-Learning: A foundational algorithm for solving Markov decision processes.
- Deep Q-Networks (DQN): Combines deep learning and reinforcement learning for complex tasks.
- Policy Gradient Methods: Directly optimize the policy of an agent for better decision-making.
How Machine Learning Models Work
Before diving into the details of each model type, let's grasp the fundamental concepts that underpin the functioning of machine learning models.
The Concept of Training and Testing Data
Machine learning models require data for both training and testing. Training data is used to teach the model to recognize patterns, while testing data assesses its performance. A crucial task is splitting the dataset into these two components, ensuring the model's ability to generalize to unseen data.
Feature Engineering and Data Preprocessing
Effective feature engineering involves selecting and transforming relevant variables (features) in the dataset to improve model performance. Data preprocessing tasks such as normalization, handling missing values, and encoding categorical variables are essential to ensure data quality and model compatibility.
The Role of Algorithms in Model Building
Algorithms are the heart of machine learning models, defining how they learn and make predictions. The choice of algorithm depends on the problem type and data characteristics. Effective model selection involves understanding the strengths and weaknesses of different algorithms.
Model Evaluation and Metrics
Evaluating model performance is a critical step in machine learning. Various metrics, such as accuracy, precision, recall, F1-score, and more, provide insights into how well the model performs. Effective model evaluation ensures that the model is reliable and fit for its intended purpose.
Types of Machine Learning Models
Now that we have a foundational understanding of machine learning, let's delve deeper into each type of machine learning model.
Supervised Learning Models
Linear Regression
Linear regression is a fundamental algorithm for predictive modeling. It's commonly used in scenarios where the goal is to predict a continuous numerical value, such as predicting house prices based on features like square footage, number of bedrooms, and location. The model fits a linear equation to the data, aiming to minimize the error between predicted and actual values.
Logistic Regression
Logistic regression is the go-to choice for binary classification tasks. It estimates the probability of an input belonging to a particular class, making it useful in scenarios like spam detection or medical diagnosis. Logistic regression applies the logistic function to a linear combination of features, mapping the result to a probability value between 0 and 1.
Decision Trees
Decision trees are versatile models used for both classification and regression tasks. They represent decisions in a tree-like structure, where each node represents a feature, and branches represent possible values. Decision trees are highly interpretable and easy to visualize, making them suitable for understanding complex decision-making processes.
Random Forest
Random forests are ensemble models built on decision trees. They combine multiple decision trees to improve predictive accuracy and reduce overfitting. By aggregating the predictions of multiple trees, random forests offer robust performance and are less susceptible to noise in the data.
Support Vector Machines (SVM)
Support vector machines (SVM) excel in binary classification tasks by finding the optimal hyperplane that maximizes the margin between two classes. SVMs are effective when the data is not linearly separable, thanks to kernel functions that map the data into higher-dimensional spaces where separation is possible.
Unsupervised Learning Models
K-Means Clustering
K-means clustering is a popular unsupervised learning technique for grouping similar data points into clusters. It's commonly used for customer segmentation, image compression, and anomaly detection. K-means iteratively assigns data points to the nearest cluster center and updates the center based on the assigned points.
Hierarchical Clustering
Hierarchical clustering organizes data into a hierarchical tree structure, allowing for nested clusters. It provides insights into the hierarchical relationships between data points and is particularly useful when exploring the structure of complex datasets.
Principal Component Analysis (PCA)
Principal component analysis (PCA) is a dimensionality reduction technique used to transform high-dimensional data into a lower-dimensional representation while preserving as much variance as possible. PCA simplifies data and can be valuable in visualization and noise reduction.
Gaussian Mixture Models (GMM)
Gaussian mixture models (GMM) assume that data is generated by a mixture of several Gaussian distributions. GMMs are often used in image segmentation, speech recognition, and density estimation. They can capture complex data distributions by modeling them as combinations of simpler Gaussian components.
Reinforcement Learning Models
Q-Learning
Q-learning is a foundational reinforcement learning algorithm that helps agents make decisions in a sequential environment. It learns a Q-table that maps state-action pairs to expected rewards, enabling the agent to choose actions that maximize long-term rewards.
Deep Q-Networks (DQN)
Deep Q-networks (DQN) combine deep neural networks with Q-learning, allowing agents to handle complex tasks and high-dimensional state spaces. DQN has achieved remarkable success in game playing and robotics, demonstrating the power of deep reinforcement learning.
Policy Gradient Methods
Policy gradient methods directly optimize the policy of an agent to maximize expected rewards. They are particularly useful in scenarios where the action space is continuous or the environment is stochastic. Policy gradient methods have applications in autonomous driving and robotic control.
Choosing the Right Machine Learning Model
Now that we've explored the diverse landscape of machine learning models, the question arises: How do you choose the right one for your problem?
Factors to Consider When Selecting a Model
Selecting the appropriate machine learning model involves considering various factors:
1. Nature of the Problem: Is it a classification, regression, or reinforcement learning problem?
2. Size and Quality of Data: Do you have enough high-quality data for training?
3. Interpretability: Do you need an interpretable model, or is predictive accuracy the primary concern?
4. Computational Resources: Can you afford the computational cost of training complex models?
5. Model Complexity: Does the problem require a simple or complex model?
6. Domain Knowledge: Are there domain-specific insights that can guide model selection?
Matching Models to Specific Problem Types
Here's a quick guide to matching machine learning models to problem types:
- Classification Problems: Use models like logistic regression, decision trees, random forests, and SVMs.
- Regression Problems: Linear regression, random forests, and support vector regression are solid choices.
- Clustering Problems: Opt for K-means clustering or hierarchical clustering.
- Dimensionality Reduction : Principal component analysis (PCA) is a go-to option.
- Reinforcement Learning: Q-learning, deep Q-networks (DQN), or policy gradient methods are suitable.
Model Selection Best Practices
When selecting a model, it's essential to follow these best practices:
- Start Simple: Begin with a simple model and progressively experiment with more complex ones.
- Cross-Validation: Use cross-validation techniques to assess model performance.
- Regularization: Apply regularization techniques to prevent overfitting.
- Ensemble Methods: Consider using ensemble methods like random forests to improve accuracy.
- Continuous Learning: Stay updated with the latest advancements in machine learning to adapt to changing needs.
Data Preparation and Preprocessing
Effective data preparation and preprocessing are vital for model success. Here's what you need to know:
Importance of Clean and Well-Prepared Data
Data quality directly impacts model performance. Clean, well-prepared data:
- Reduces errors and noise in predictions.
- Enhances model generalization.
- Improves the reliability of insights drawn from the model.
Data Cleaning Techniques
Data cleaning involves identifying and handling issues in the dataset, including:
- Removing duplicates.
- Handling missing values (imputation or removal).
- Dealing with outliers.
- Correcting inconsistencies and errors.
Feature Engineering Strategies
Feature engineering aims to create informative features from raw data. Strategies include:
- Creating new features that capture domain knowledge.
- Transforming features (e.g., scaling or normalizing).
- Encoding categorical variables.
- Reducing dimensionality using techniques like PCA.
Building and Training Machine Learning Models
Now that we've laid the groundwork let's dive into building and training machine learning models.
Steps Involved in Building a Machine Learning Model
Building a machine learning model typically involves these steps:
- Data Collection: Gather relevant data for your problem.
2. Data Preprocessing: Clean, preprocess, and prepare the data.
3. Feature Selection: Choose the most relevant features.
4. Model Selection: Select an appropriate machine learning model.
5. Hyperparameter Tuning: Optimize model hyperparameters.
6. Model Training: Train the model on the training data.
7. Model Evaluation: Assess model performance using test data.
Hyperparameter Tuning
Hyperparameters are settings that control the learning process. Techniques like grid search or random search can help find optimal hyperparameters. Proper tuning prevents overfitting and ensures the model generalizes well.
Cross-Validation Techniques
Cross-validation assesses model performance on multiple subsets of the data. Common techniques include k-fold cross-validation and stratified sampling. Cross-validation provides a more reliable estimate of model performance.
Model Evaluation and Interpretation
Evaluating and interpreting machine learning models is essential for ensuring their reliability and understanding their decision-making process.
Common Evaluation Metrics
Different tasks require specific evaluation metrics:
- Classification:
- Accuracy: The proportion of correctly classified instances.
- Precision: The ratio of true positives to all predicted positives.
- Recall: The ratio of true positives to all actual positives.
- F1-score: The harmonic mean of precision and recall.
- Regression:
- Mean Absolute Error (MAE): The average absolute difference between predicted and actual values.
- Mean Squared Error (MSE): The average squared difference between predicted and actual values.
- Root Mean Squared Error (RMSE): The square root of MSE.
Interpretability and Explainability of Models
Interpretable models provide insights into their decision-making process. While some models, like decision trees, are inherently interpretable, others require additional techniques for explainability. Explainable AI methods, such as LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations), shed light on complex models' predictions.
Avoiding Overfitting and Underfitting
Overfitting occurs when a model learns noise in the training data, leading to poor generalization. Underfitting, on the other hand, occurs when a model is too simple to capture the underlying patterns. Techniques like regularization, cross-validation, and monitoring learning curves help mitigate these issues.
Real-world Applications of Machine Learning Models
Machine learning models have made a profound impact on various industries, revolutionizing the way businesses operate and improving people's lives.
Case Studies and Examples
Let's explore real-world applications of machine learning models:
Healthcare
- Disease Diagnosis: Machine learning aids in the early diagnosis of diseases such as cancer and diabetes.
- Drug Discovery: Predictive models accelerate drug discovery by identifying potential compounds.
- Personalized Medicine: Tailored treatment plans based on patient data improve healthcare outcomes.
Finance
- Fraud Detection: ML models detect fraudulent transactions in real-time, reducing financial losses.
- Algorithmic Trading: Predictive models inform investment decisions and optimize trading strategies.
- Credit Scoring: ML models assess credit risk, streamlining loan approval processes.
E-commerce
- Recommendation Systems: Personalized product recommendations boost sales and customer satisfaction.
- Inventory Management: Predictive models optimize inventory levels and reduce overstocking.
- Customer Churn Prediction: ML models help retain customers by identifying those at risk of leaving.
Autonomous Vehicles
- Self-driving Cars: Reinforcement learning and computer vision enable autonomous navigation.
- Traffic Management: ML models optimize traffic flow, reducing congestion and accidents.
- Vehicle Maintenance: Predictive maintenance models prevent breakdowns and reduce maintenance costs.
Natural Language Processing (NLP)
- Language Translation: NLP models enable real-time translation between languages.
- Sentiment Analysis: ML models gauge public sentiment from social media data.
- Chatbots and Virtual Assistants: NLP-powered chatbots provide automated customer support.
Impact on Business and Society
The adoption of machine learning models has far-reaching implications:
- Improved Decision-Making: Data-driven insights inform strategic decisions and resource allocation.
- Enhanced Customer Experiences: Personalization and recommendation systems enhance user satisfaction.
- Increased Efficiency: Automation of repetitive tasks boosts productivity and reduces operational costs.
- Societal Advancements: ML models drive advancements in healthcare, education, and environmental conservation.
Challenges and Limitations of Machine Learning Models
While machine learning offers immense potential, it also poses challenges and limitations.
Ethical Considerations in Machine Learning
Machine learning models can inadvertently perpetuate bias and discrimination present in training data. Addressing ethical concerns is paramount to ensure fairness and equity.
Bias and Fairness Issues
Biased data can lead to biased predictions. Mitigating bias and ensuring fairness in AI models require careful data curation and algorithmic fairness considerations.
Data Privacy Concerns
As machine learning models increasingly rely on personal data, safeguarding privacy becomes critical. Privacy-preserving techniques and compliance with regulations (e.g., GDPR) are essential.
Future Trends in Machine Learning Models
The field of machine learning is dynamic and continuously evolving. Here are some future trends to watch for:
Advancements in Deep Learning and Neural Networks
Deep learning, a subset of machine learning, continues to advance. Expect more breakthroughs in areas like natural language processing, computer vision, and reinforcement learning.
The Role of AI and ML in Emerging Technologies
Machine learning models are integral to emerging technologies such as autonomous vehicles, edge computing, and quantum computing. These technologies will shape the future of various industries.
Potential Breakthroughs on the Horizon
Quantum machine learning, explainable AI, and AI ethics are research areas with the potential for groundbreaking discoveries. Stay tuned for innovations that address current challenges and reshape the landscape.
Conclusion
In this comprehensive guide, we've explored the vast realm of machine learning models, from their foundational principles to real-world applications and future trends. Machine learning empowers businesses to make data-driven decisions, enhances our daily lives, and drives innovation across industries.
As you embark on your journey into the world of machine learning, remember that it's a dynamic field with endless possibilities. By understanding the various types of machine learning models, their applications, and best practices, you can harness the power of AI to solve complex problems and shape a brighter future.
Additional Resources and References
For further learning and exploration, consider the following resources and references:
- Books:
- "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron
- "Introduction to Machine Learning with Python" by Andreas C. Müller & Sarah Guido
- Courses:
- Coursera's "Machine Learning" by Andrew Ng
- Websites:
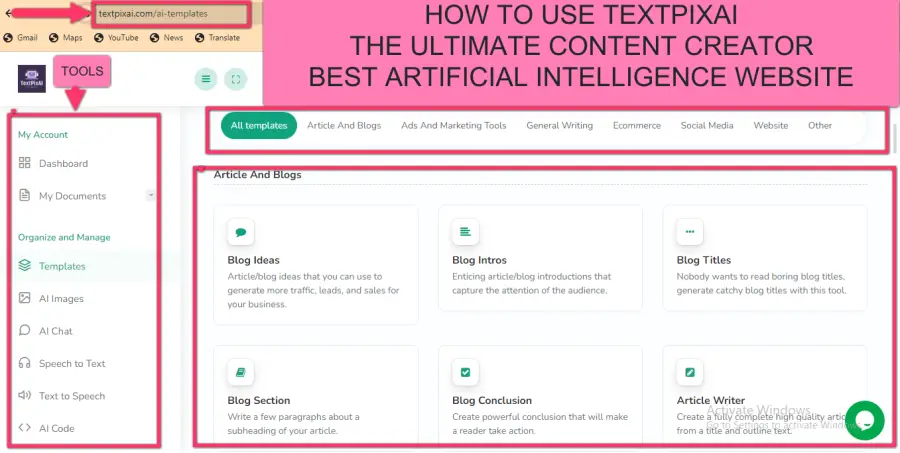
- TextPixAI (textpixai.com)
- Kaggle (kaggle.com)
- Stanford University's Machine Learning Course
With these resources and your newfound knowledge, you'll be well-equipped to embark on your machine-learning journey and contribute to the exciting developments in this field.